
The first row is the reference images. The second row is the generated images.
Abstract
Pose-guided person image synthesis aims to synthesize person images by transforming reference images into target poses. In this paper, we observe that the commonly used spatial transformation blocks have complementary advantages. We propose a novel model by combining the attention operation with the flow-based operation. Our model not only takes the advantage of the attention operation to generate accurate target structures but also uses the flow-based operation to sample realistic source textures. Both objective and subjective experiments demonstrate the superiority of our model. Meanwhile, comprehensive ablation studies verify our hypotheses and show the efficacy of the proposed modules. Besides, additional experiments on the portrait image editing task demonstrate the versatility of the proposed combination.
Network Architecture
Deformation Estimation Module
The Deformation Estimation Module is proposed to estimate the correspondence between the reference image and the target image. The Attention Correlation Estimator and the Flow Field Estimator is first employed to estimate the attention map and the flow field between the reference image and the target image. Then the Combination Map Generator is used to predicts the combination maps to select from the warping results of the attention operation and the warping results of the flow-based operation.
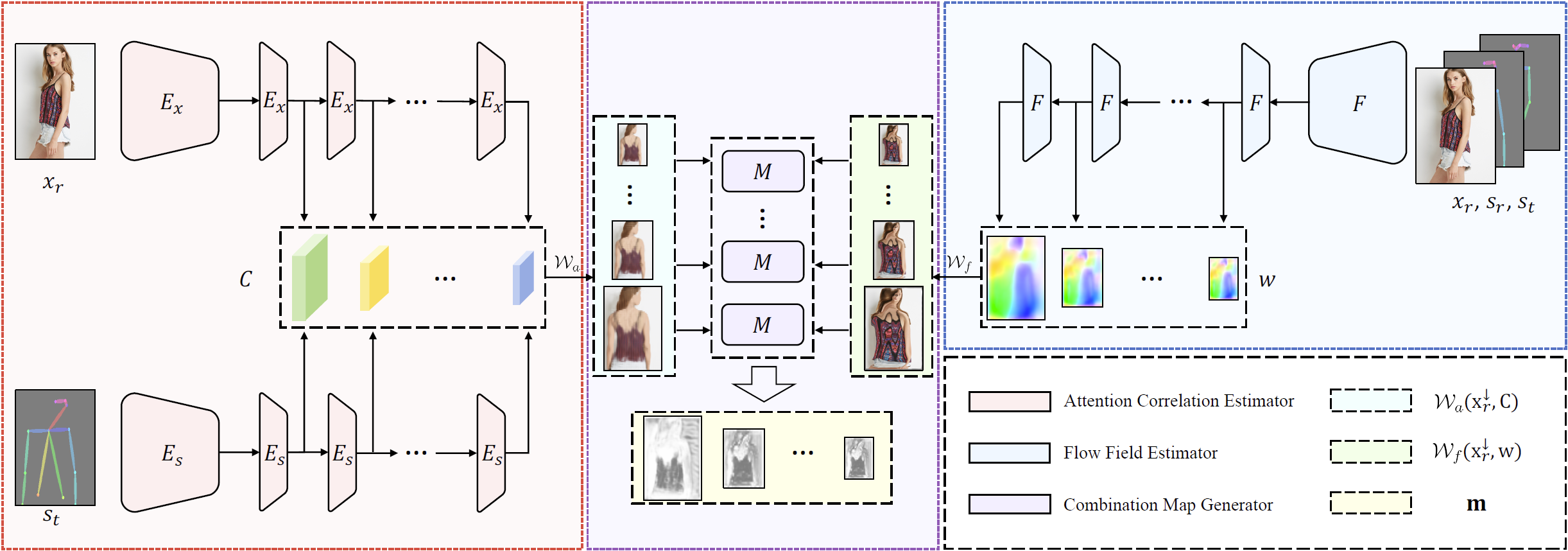
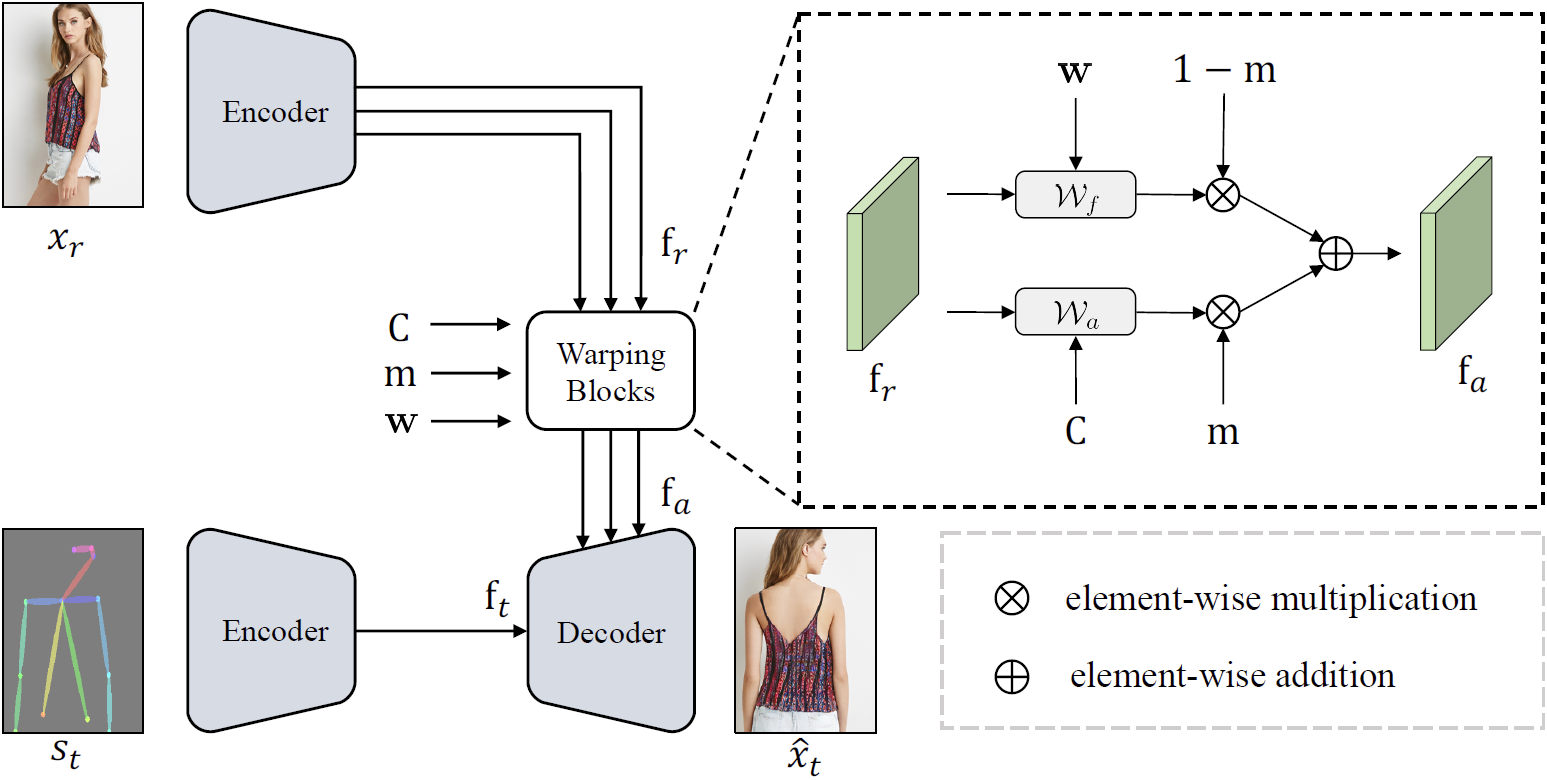
Image Synthesis Module
The image Synthesis Module is used to synthesis the final output by rendering target skeletons with reference texture. The architecture of this module is shown below. The warping block reassembles the reference neural textures according to the estimate deformations. Then the vivid neural textures are added to the feature maps extracted from the target skeletons to synthesis a realistic image.
Results
The In-shop Clothes Retrieval Benchmark of the DeepFashion dataset is used in our experiments which is the same as GFLA. A total of 8570 pairs are randomly selected for testing. We provide all the qualitative results here.
Pose-Guided Person Image Synthesis

From Left to Right: Source, Target Pose, Target Image, VU-Net, Def-GAN, Pose-Attn, Intr-Flow, ADGAN, GFLA, Ours.
Ablation Study

From Left to Right: Source, Target Image, Baseline Attn Model, Flow Model, w/o face, Full Model.
Portrait Image Editing
